
As the AI boom progresses, there is a definite transition, moving intelligent processes to end devices from their original home in the cloud and big data centers with tremendous compute power.
Organizations all across the globe are recognizing the need for machine learning practices on mobile devices like smartphones and the ability to perform powerful AI-enabled tasks natively on gadgets, machines, vehicles, and more. Qualcomm is one such tech giant trying to shape the edge AI sector with its new line of ML offerings.
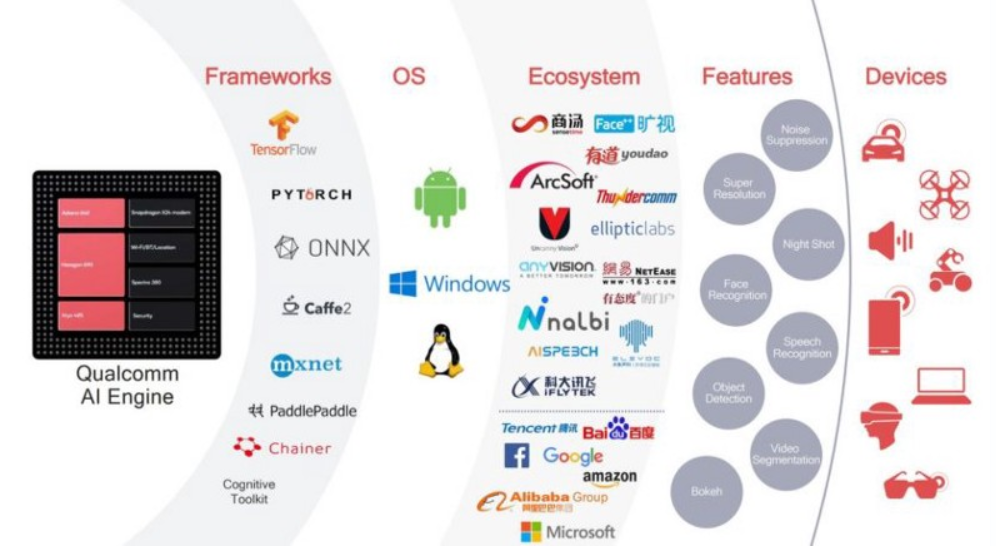
Back in 2017, Qualcomm released their AI Engine to help developers provide better machine learning-based features to their applications. Dedicated for Snapdragon processors, The Qualcomm Artificial Intelligence (AI) Engine is a collection of hardware and software modules that can be utilized by developers to “create and accelerate their AI applications and devices” both online and offline. The AI engine’s software bucket consists of three major offerings. We’ll cover each of them here.
Neural Processing SDK
Qualcomm has come up with this particular software development kit to aid developers in achieving higher performance of trained neural networks on devices with Snapdragon processors while saving time, effort and resources.
It offers tools for model conversion and execution as well as APIs for targeting the processor core with the appropriate power and performance profile matching the desired user experience. The SDK typically offers support for convolutional neural networks and custom layers. It makes use of the Snapdragon processor’s heterogeneous computing capabilities, allowing much more efficient performance of neural networks on the device without any connection to the cloud.
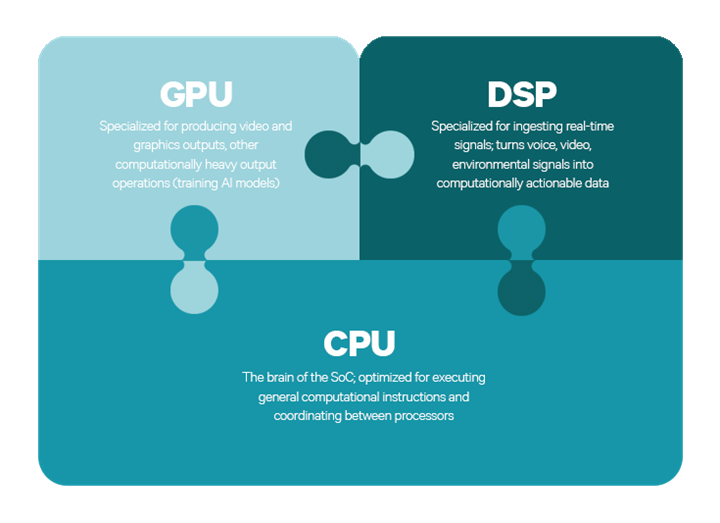
It supports neural network models trained in Caffe/Caffe2, ONNX, or TensorFlow on Snapdragon devices, whether it be a CPU, GPU, or DSP.
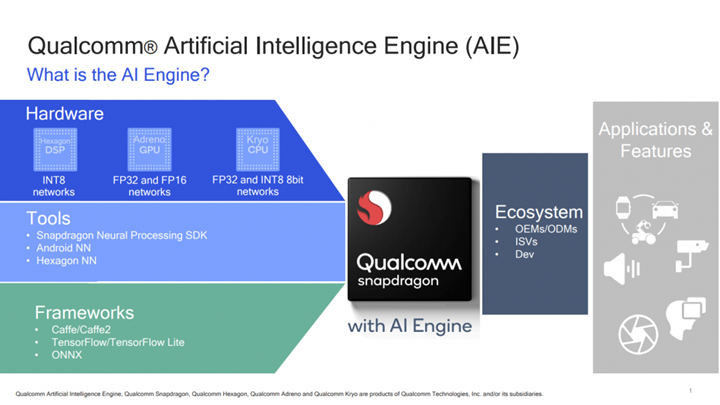
Essentially, the Neural Processing SDK does the heavy lifting needed to run neural networks on Snapdragon mobile platforms, which gives developers more time and resources to focus on building new and innovative user experiences. Some of the constituents of the SDK are:
- APIs for controlling loading, execution, and scheduling on the runtimes
- Desktop tools for model conversion
- Performance benchmarks for bottleneck identification
- Android and Linux runtimes for neural network model execution
- Acceleration support for Qualcomm Hexagon DSPs, Adreno GPUs, and CPUs
Snapdragon Developer Tools
This module consists of a number of SDK packages such as the Snapdragon Profiler to help identify app performance issues, the Snapdragon Power Optimizer to enhance battery life, and the Snapdragon Heterogenous compute, the user library. Its main use is to optimize apps to run on Snapdragon processors.
Hexagon DSP SDK
The Hexagon DSP targets the features and performance of multimedia software, ushering in optimizations that allow audio, imaging, embedded vision, and heterogeneous computing acceleration on the Hexagon DSP embedded in Snapdragon processors.
It allows upgraded multimedia user experiences by providing improvements in the power dissipation and performance of audio, imaging embedded vision, video, and other computationally-intensive applications. It has tons of features such as the Hexagon Neural Network library, which works exclusively with the Hexagon Vector Processor.
The Snapdragon Neural Processing Engine was the very first deep learning software framework designed for Snapdragon mobile platforms. Developers can make use of the SDK to inculcate deep learning activities such as style transfer and computer vision filters for use in AR, scene detection, face recognition, natural language processing, object tracking, text recognition and tons of other use cases.
The Snapdragon Neural Processing Engine found its way into top industry applications — for example, Facebook’s integration of SNPE into the camera of the Facebook app to accelerate Caffe2-powered AR features. Reportedly, Facebook enhanced performance five fold on Adreno GPUs through its use of SNPE.
A peek at what SNPE can achieve
As a software accelerated runtime for the execution of deep neural networks on Snapdragon devices, SNPE comes loaded with the following capabilities:
- Execute an arbitrarily deep neural network
- Execute the network on the SnapdragonTM CPU, the AdrenoTM GPU, or the HexagonTM DSP.
- Convert Caffe, Caffe2, ONNXTM and TensorFlowTM models to a SNPE Deep Learning Container (DLC) file
- Quantize DLC files to 8-bit fixed point for running on the Hexagon DSP
- Analyze the performance of the network with SNPE tools
- Integrate a network into applications and other code via C++ or Java
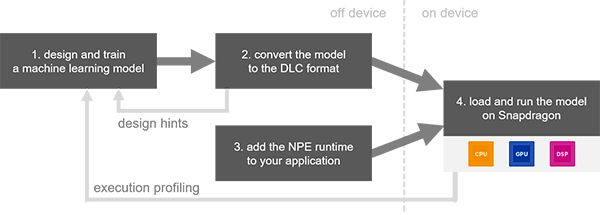
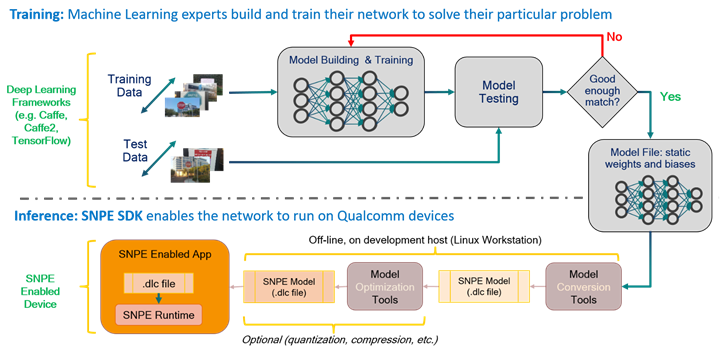
The workflow of SNPE is simple. Feed it a model trained on any number of popular deep learning frameworks (SNPE supports Caffe, Caffe2, ONNX, and TensorFlow). This trained model is converted into a .dlc file that can be loaded into the SNPE runtime.
The .dlc file can then be used to perform forward inference passes using one of the Snapdragon-accelerated compute cores. You can find a list of supported Snapdragon devices here.
Setting up
Let’s take a look at how to get ready to deploy a model successfully with SNPE. Currently the SNPE SDK development environment is limited to Ubuntu 16.04. It requires setting up either Caffe, Caffe2, ONNX, or TensorFlow.
Depending on your preference, you can follow instructions for building Caffe on Ubuntu, or otherwise install TensorFlow on Ubuntu; or alternatively, ONNX. Python 3 needs to be installed and set as an environment variable.
Machine learning frameworks usually use specific formats for storing neural networks. SNPE supports these various models by converting them to a framework-neutral deep learning container (DLC) format. For example, take a model trained in TensorFlow. It exists as either a frozen TensorFlow file or a pair of checkpoint and graph meta files. The snpe-tensorflow-to-dlc tool converts a frozen TensorFlow model or a graph meta file into an equivalent SNPE .dlc file. The following command will convert an InceptionV3 TensorFlow model into a SNPE .dlc file:
Like most neural network runtime engines, SNPE uses layers as building blocks. TensorFlow, on the other hand, defines a neural network as a graph of nodes, and a layer is defined as a set of nodes within the graph. So in order to properly convert a TF graph to a .dlc file, nodes belonging to a layer must be defined in a unique TensorFlow scope.
The snpe-framework-to-dlc conversion tool simply converts non-quantized models into a non-quantized .dlc file. Quantizing a model is a separate procedure. The snpe-dlc-quantize tool is used to quantize the model to one of the supported fixed-point formats. For example, the following command will convert an InceptionV3 .dlc file into a quantized InceptionV3 .dlc file:
A representative set of input data needs to be used as input into snpe-dlc-quantize. Usually providing 5–10 input data examples in the input_list parameter is sufficient and practical for quick experiments.
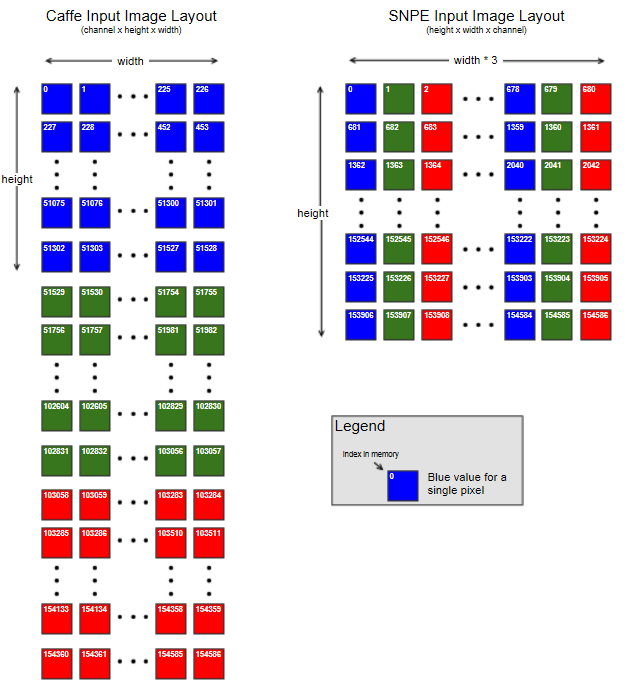
In addition to converting the model, SNPE also requires the input image to be in a specific format that might be different from the source framework. For example, in Caffe, the image is presented as a tensor of shape “batch x channel x height x width” while in SNPE, the image must be presented as a tensor of shape “batch x height x width x channel”.
A short example
The SNPE documentation is rich with dozens of tutorials and examples, depicting running different networks in various languages and runtimes. For the sake of an example, let us see how to run an InceptionV3 model on Android using the CPU runtime.
The Android C++ executable is run with the following commands on an adb shell:
This will create the results folder: /data/local/tmp/inception_v3/output. To pull the output:
You can check the classification results by running the following Python script on a linux host:
The output should look like the following, showing classification results for all the images:

Takeaways
The Snapdragon Neural Processing Engine works great as a software-accelerated runtime that executes deep neural networks on Snapdragon devices. It offers efficient executions, lots of support for models, and a bunch of developer tools.
It does suffer from certain limitations but is of great value if you happen to have a pre-trained model and need to run a neural network on a Snapdragon-powered platform. SNPE provides the ability for users to plug in custom neural network operations. which can be natively executed on supported hardware. SNPE also provides the infrastructure to execute these operations seamlessly with little to no overhead.

Comments 0 Responses