
NLP is a hot topic right now in the deep learning and machine learning communities, thanks to the incredible development of Transformer-based neural networks like BERT and GPT-2.
Natural language processing (NLP) gives programs and applications the ability to understand spoken and written human language.
Developing NLP applications is difficult because traditionally, computers are designed for humans to interact with them in precise, unambiguous, and highly-structured programming languages, or by using a limited number of set spoken commands.
Human speech isn’t always precise—it’s often ambiguous and its linguistic structure can depend on a large number of complex variables, notably slang, regional dialects, and social context.
Current NLP approaches are based on deep learning, an artificial intelligence branch that examines data structures and uses them to improve the understanding of a given application.
Deep learning models require huge volumes of annotated data to learn and identify relevant correlations, and assembling this type of big data is currently one of the main hurdles facing NLP.
Previous approaches to NLP were more rule-based and consisted of teaching simpler (pure statistical) machine learning algorithms the words and phrases to search for in the text, with specific responses being generated when these phrases were found.
Deep learning is a more flexible, more intuitive approach—algorithms learn to identify the speaker’s intention through numerous examples, much like a child would to learn to speak.
In this article, I’ll give a primer for Transformers (and BERT specifically). Then, I’ll train a BERT network on rated comments from Amazon’s dataset, to output a final model capable of correctly labeling comments and tweets, and create an API that will process Tweets and make predictions on them.
Finally, I’ll create an iOS application that will consume the API. I’ve also included the source code for other applications (Android, web, and desktop) that leverage the same API and look similar to the iOS counterpart.
Overview
- Transformers
- What is BERT?
- BERT architecture
- The dataset
- Transformers package from Hugging Face
- The Flask API
- Building the iOS Application
- Other applications
- Conclusion
I have included code in this article where it is most instructive. Full code and data can be found on my GitHub page or the Colab notebook included in the article for training the model.
Transformers
1. Attention-based algorithms
In machine learning, an attention mechanism is inspired by how our own cerebral cortex functions. When we analyze an image to describe it, our attention instinctively focuses on a few areas that we know contain important information. We do not look at every part of the picture with the same sharpness. This mechanism is therefore a means of saving processing resources when faced with complex data to analyze.
Similarly, when an interpreter translates text from a source language into a target language, they know from experience which words in a source sentence are associated with a certain term in the translated sentence.

This attention mechanism is now an integral part of most modern semantic analysis solutions and has been identified by many AI experts as one of the main R&D trends in 2019.
Not only does AM boost the performance of several deep learning algorithms, it also offers the beginning of a solution to the thorny problem of interpreting the operations of RNNs, reduced until recently to black boxes.
2. Word embedding
Word embedding refers to a set of machine learning techniques that aim to represent words or sentences of a text by vectors of real numbers, described in a vector model (or vector space model). These new representations of textual data have improved the performance of various methods for natural language processing, such as topic modeling and sentiment analysis.
Word embedding is based on a linguistic theory known as distributional semantics. This theory posits that a word is characterized by its context, which is to say by the words that surround it. Thus, words that share similar contexts also share similar meanings. Word embedding algorithms are most often used to describe words through digital vectors, but they can also be used to construct vector representations of whole sentences, using biological data such as DNA sequences, or represented networks, like graphs.
There are several approaches to word embedding. The first date back to the early days of AI and are based on methods of dimensionality reduction. More recently, new techniques based on probabilistic models and neural networks, such as Word2Vec, have made it possible to obtain better performance.
Word embedding creates a vector representation of a word that we’re able to manipulate using linear algebra. One common problem is that words can have different meanings that depend on their contexts. For example, the word “Lynch” has a different meaning in the sentence:
Using old encoders, the world “Lynch” would have the same vector. the sentence should be converted to a sequence of vectors instead, with one vector per word. Additionally, the context of words will be considered during the encoding process, with a classifier that’ll be used to weight words through attention. For instance, the word “Lynch” is going to be treated and encoded differently, given the context.
What is BERT?
BERT stands for “Bidirectional Encoder Representations from Transformers”. This model architecture came from Google AI researchers at the end of 2018 and has numerous key qualities:
- More efficient than its predecessors in terms of results (even if it’s getting harder to keep up with the new transformers).
- More efficient than its predecessors in terms of learning speed.
- Once pre-trained, unsupervised (initially with everything — absolutely everything — in the English-speaking corpus of Wikipedia), it has its own linguistic “representation”. It’s then possible, on the basis of this initial representation to customize it for a specific task. It can be trained incrementally (supervised this time) to specialize the model quickly and with little data.
- Very versatile (classification, Q&A, translation, etc).
With word embedding, we need to create a dense representation of words. But in the prior section, we discussed how word embedding cannot explore the context of the neighboring words well. Additionally, we want a representation model that’s multi-purposed.
In BERT, a model is first pre-trained with data that needs no human labeling. Once it’s done, the pre-trained model outputs a dense representation of the input.
To access other NLP tasks, like QA, we modify the model by simply adding a shallow deep layer connecting to the output of the initial model. Then, the model is retrained with data and labels that are specific to the task.
In short, there is a pre-training step during which we create a dense representation of the input (look at the diagram below). The second phase then retrains the model with task-specific data to address the target NLP problem.

BERT architecture
BERT uses the part of the Transformer network architecture introduced by the paper “Attention is all you need”. The advantage of this architecture is that it makes it possible to deal with relationships between distant words better than recurring networks (LSTM / GRU).
On the other hand, the network cannot process sequences of any length; instead, it has a finite entry dimension that cannot be too large (about 300–500 words in most networks). Otherwise, the network is unable to learn anything significant in a reasonable amount of training time. This limit can be circumvented by re-introducing recurring networks over it—for example, Transformer-XL—but we won’t be covering that in this article.
Google researchers have proposed several pre-trained versions of their model. To facilitate the explanations herein, we’ll use the model that uses only lowercase letters, with a single language, 12 layers, a hidden layer dimension of 768 and 12 attention heads (BERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parameters).
Don’t worry if you don’t know what all this means—we’ll explain more thoroughly later. The purpose of this article is to present you with a high-level view of the BERT architecture.
As mentioned above, BERT is made up of 12 layers, so let’s see what these famous layers are made of based on a Transformer architecture. In order, we have the following sublayers:
- The attention block
- The normalization layer
- The feed forward layer
- The normalization layer
Embedding
The first step is the embedding. This allows us to transform our words into vectors. The entry for BERT is the sum of 3 embeddings: the embedding token, the embedding position, and the embedding segment.
Token Embedding
The embedding token provides information on the content of the text. The first thing to do is to transform our text into a vector. To avoid having too large of a vocabulary size and to be able to deal with new words, they use a token system. A token is one or more letters—we’ll see some examples later. To find the tokens that will break down the input words, we can use the BPE algorithm (bytes pair encoding). BERT uses another algorithm but the principle remains similar.
To start, we have to find the most frequent letter pair in our word corpus. For example, here we’ll say that it is “Lynch”, so we replace this pair with a new token—let’s name it X. We then replace all occurrences of “Lynch” with X. And we start again until we reach the number of tokens that suits us (30,000 tokens for BERT). In addition, we always add the letters alone as a token, which allows us to handle words never encountered.
Once we have our token list, we can deterministically transform our text into a token and vice versa. For this, we replace the occurrences of the different tokens, from the largest to the smallest. In the worst case, we represent our word by each of its letters. Each token can now be encoded on a vector of size 30,000 with zeros except in one place where we put the number one—that’s called one-hot encoding.
Masked Language Model (LM)
BERT learns by masking 15% of the WordPiece, then 80% of those get replaced with a “Mask” token, 10% with random tokens, and the rest keep the original word. The loss is then defined as how well the model predicts the missing word.
The LM task forces the model to encapsulate a significant part of NLP as well aspects of syntax and semantics. To make such a model, add a softmax layer that converts the hidden vector of the last layer of the Transformer into a probability of the vocabulary words.
The dataset
In order to fulfill the main objective of this project, it’s essential to find some text that could be similar to the structure of a 240-character tweet. Although there is no limit to an Amazon comment, I chose to train our model on comments taken from Amazon’s product reviews for the following reasons:
- The grammar/spelling is as questionable as what a Twitter user might use.
- Reviews reflect an opinion on a given product, which is what our project is aiming to achieve for brands.
- Huge amount of reviews available.

The dataset available regroups more than 70 million reviews for 24 categories; however, due to limited computational power, I chose to limit the number of reviews to a maximum of 80, 000, evenly distributed between neutral, negative, and positive reviews.
As you can see in the dataset snapshot, we have access to the overall rating of the reviewer towards the product. Amazon has a 5-star rating system, which I used as follows to label every review:
- 1 or 2 stars: negative review
- 3 stars: neutral review
- 4 or 5 stars: positive review
I narrowed the categories to the following ones, in order to be as diverse as possible while also being close to what Twitter users could discuss in their Tweets:
- Electronics
- Sports and outdoors
- Automotive
- Cellphones and accessories
- Clothing, shoes, and jewelry
I decided to use different datasets, size-wise, in order to determine whether or not the size matters when it comes to training our model (obviously it should). Every small subset that I built has the following features:
- Equally distributed number of reviews from each category
- Equally distributed number of reviews for each label (positive/negative/neutral)
The Amazon dataset can be found here:
Transformers package from Hugging Face
Hugging Face has a high-level interface to work with Transformers, and they even have pre-trained models.
We’ll use PyTorch version, and we’ll also use the small network because we don’t have access to unlimited computational resources. We’re also going to Google Colab, which is a free cloud service where we can write and execute Python code in our browser. It gives us access to a maximum of 24 Gb of memory, a 500 Gb hard drive, but most importantly, a Tesla K80 GPU that is mostly used for deep learning applications.

The code is on the Jupyter Notebook with comments, here:
Flask API
The Twitter API allows you to access to different Twitter features without accessing the website.
Below is an example of what a classic call to the API returns:

The API is pretty similar to the one I’ve made and explained in the article below:
The final API will look like this:

There is a summary of neutral, positive, and negative tweets. All this information will be parsed in all the applications in order to produce a bar chart.
iOS Application
The idea here is to send a query to the API and receive a summary of the sentiments of the tweets fetched from Twitter’s search API. Finally, we will show a distribution of the sentiments in a bar chart.
The main argument of using an API is that we can create different presentation layers, like a mobile application or even a desktop application. Developers can thus leverage a powerful model through an API and allow their users to access it on a number of platforms. Additionally, they‘re then able to constantly update the model without any end-user update through Apple’s App Store or the Google Play Store.
Create a new project
To begin, we need to create an iOS project with a single view app. Make sure to choose Storyboard in the “User interface” dropdown menu (Xcode 11 only):
Now we have our project ready to go. I don’t like using storyboards myself, so the app in this tutorial is built programmatically, which means no buttons or switches to toggle — just pure code 🤗.
To follow this method, you’ll have to delete the main.storyboard and set your SceneDelegate.swift file (Xcode 11 only) like so:
func scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions) {
// Use this method to optionally configure and attach the UIWindow `window` to the provided UIWindowScene `scene`.
// If using a storyboard, the `window` property will automatically be initialized and attached to the scene.
// This delegate does not imply the connecting scene or session are new (see `application:configurationForConnectingSceneSession` instead).
guard let windowScene = (scene as? UIWindowScene) else { return }
window = UIWindow(frame: windowScene.coordinateSpace.bounds)
window?.windowScene = windowScene
window?.rootViewController = ViewController()
window?.makeKeyAndVisible()
}With Xcode 11, you’ll have to change the Info.plist file like so:

You need to delete the “Storyboard Name” in the file, and that’s about it.
Setup ViewController():
The application has two main components:
- Input field: We will use the input field to type in a search query and send it to the API.
- Bar chart: The bar chart will show the distribution of Tweet’s sentiments (positive, negative, and neutral). I’m using a widely-used package called “Charts”, which is mainly inspired by the Android equivalent:
API calls
We can make a pretty easy and straightforward call using URLRequest, Apple’s native API that includes the HTTP methods (GET, POST, DEL…) and the HTTP headers.
I created two structs in order to directly map the Flask API without parsing a long JSON file:
We need a GET call in order to get the summary of predictions and update the chart:
func getPrediction(brand: String) {
let serverAddress = "https://127.0.0.1:5000/(brand)"
var request = URLRequest(url: URL(string: serverAddress)!)
request.httpMethod = "GET"
request.addValue("application/json", forHTTPHeaderField: "Content-Type")
let session = URLSession.shared
let task = session.dataTask(with: request, completionHandler: { data, response, error -> Void in
do {
guard let data = data else {return}
print(data)
let pred = try JSONDecoder().decode(Prediction.self, from: data)
DispatchQueue.main.async(execute: {
self.prediction = pred
self.setupBarChart(positive: pred.positive, negative: pred.negative, neutral: pred.neutral)
self.setupLabelsData(positive: pred.positive, negative: pred.negative, neutral: pred.neutral, total: pred.number_of_tweets)
})
} catch {
print("error")
}
})
task.resume()
}Final result
In order to stay on good terms with Twitter, I limited the number of tweets to 20.
The evaluation of the model will be mainly done in the Python code—the way I really like to test models it to create my own test dataset with a mix of long, short, easy, and complex sentences. The presentation layer will not determine the level of accuracy nor the level of precision. You’ll need to iterate through different examples and see where the model gets confused.

Other applications
It would probably take too long to explain each and every possible application of this architecture, but here I’ve got you started with the source code for a multitude of applications (Android, web, and MacOS).
Android application
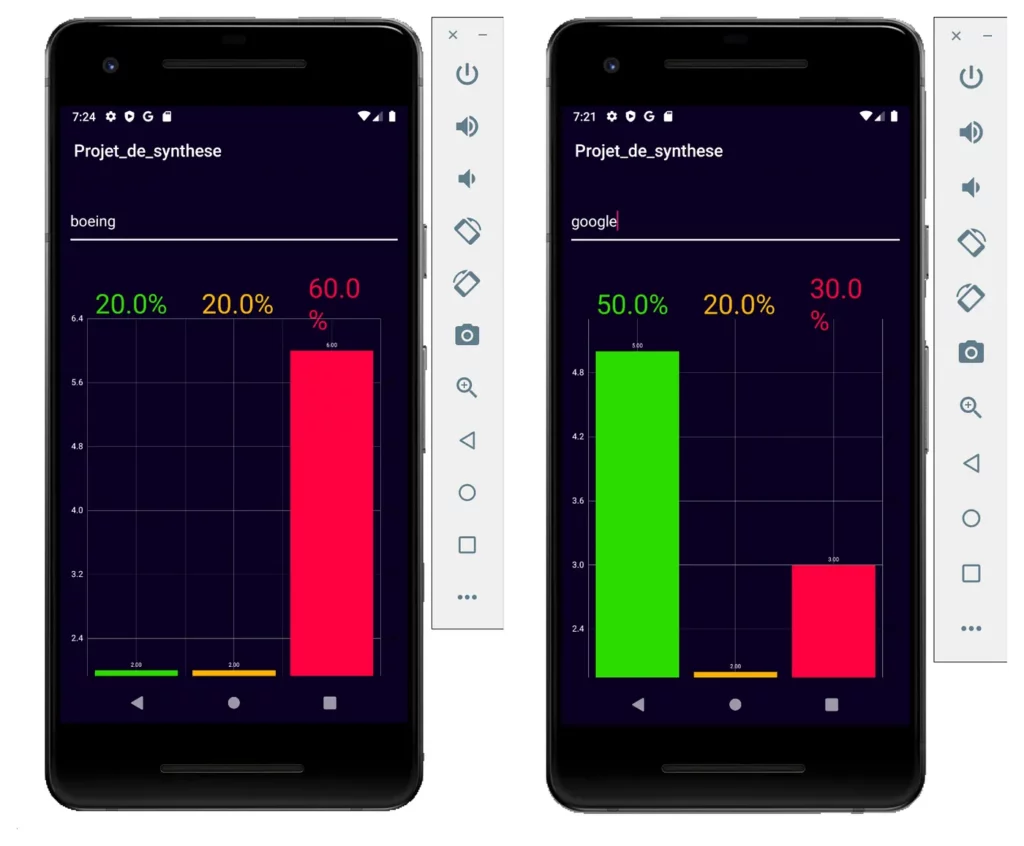
Web application
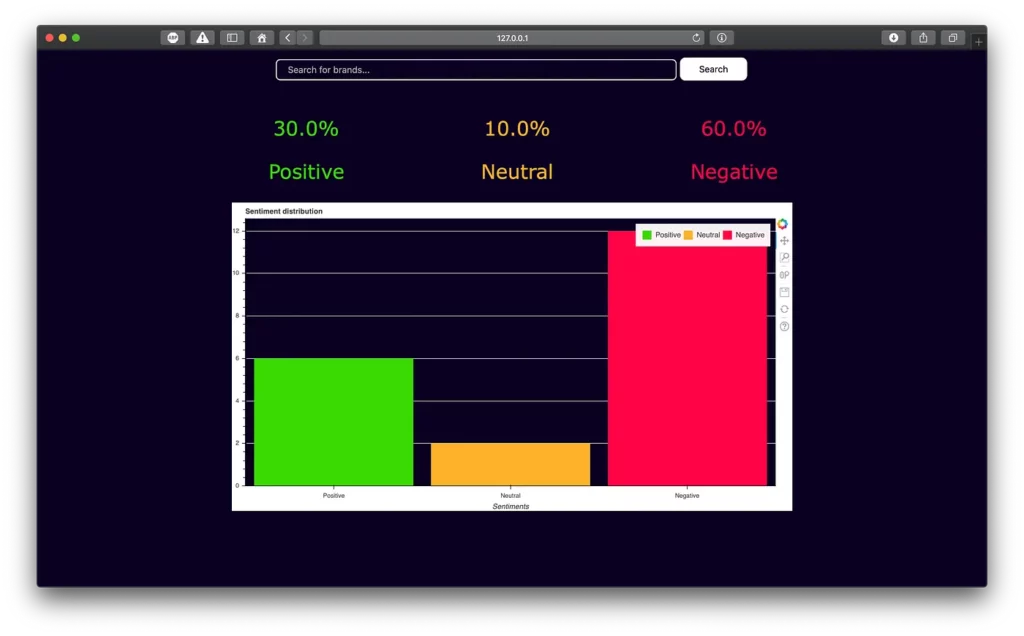
MacOS application

Conclusion
As a conclusion, here’s a fascinating question raised by the NLP community:
Yoshua Bengio, one of the founding fathers of deep learning and scientific director of the prestigious Montreal Institute for Learning Algorithms (MILA), seriously doubts it and recommends experimenting now with a so-called Grounded Language Learning approach, which consists of learning a language by sensory experience rather than by reading a huge amount of text only.

Common intuition suggests to us that an immense reservoir of common sense— that which allows us to move in a complex physical and social world—is not available in any body of text, however vast it might be. In addition, a simple argument drawn from information theory shows that certain languages are rigorously “unlearnable”, even though we can semantically encode knowledge capable of describing a whole universe, e.g. dialects.
The strategy pursued by Bengio’s team consists of initiating such “embodied language learning” in virtual worlds that are extremely simplified, where learning will be fast and then continue in the real world.

Comments 0 Responses