
In [a previous tutorial], the Levenshtein distance was used in an Android app to suggest words as a user types to automatically complete the word and save time.
In this follow-up tutorial, the suggestions will be enhanced by comparing the text the user is typing to words that are likely to be a match. Moreover, the app will support early exit if the distance exceeds a pre-defined threshold, which helps save time and enhance the suggestions.
The sections covered in this tutorial are:
- Enhancing suggestions based on word length
- Calculating the distance
- Early exit
Enhancing suggestions based on word length
The Android app created in the previous tutorial compares the user input with the words in the dictionary regardless of their lengths.
So if the user entered a word of length N, then it will be compared to all words in the dictionary, regardless of whether the lengths are close to the user input or not. As a result, it might compare the user input con (3 characters) with the word abbreviation (12 characters).
If the difference in lengths between the user input and a suggested word is high, then it’s less likely that such a word will be a good suggestion. We have to deal with such a situation.
One approach is to exclude the comparison between words when the absolute difference in their lengths exceeds a predefined threshold, like T=4 characters, for example. In this case, then, the user input con will not be compared with the word abbreviation anymore.
But this is also not the proper way to approach this problem. Why not? Let’s discuss.
The overall objective of the project is to save a user from typing entire words by making suggestions to automatically complete their inputs with the highest possible accuracy.
If a condition is set to just compare the user input to dictionary words when the absolute difference is just T characters, then the user will not be prompted by good suggestions unless the absolute difference is T characters or less.
For example, If the user’s objective is to type the word congratulations while T=4, then the user has to type congratulat in order to make the absolute difference between the input and the dictionary word 4 characters.
As such, the word congratulations will appear in the list of suggestions, but after the user enters many characters (11 in this case). We need to give good suggestions when entering the fewest possible number of characters.
Note that increasing the threshold T to a higher value like 10 will allow the user input to be compared with the word congratulations at an earlier stage, but unfortunately this approach suffers because it compares the user input to words that will not likely to be good suggestions, since this difference in the number of characters is large (10 characters).
Currently, the user input is compared with entire dictionary words. So if the user entered cong, it will be compared with the complete word congrationations and the Levenshtein distance, in this case, is 12. To lower this distance, the user has to type more characters, but this is against the primary goal of helping the user’s time typing many characters. Here is a better and rational solution:
If the user enters cong (4 characters), then it will not be compared with the complete word congratulations, but instead with its first 4 characters. Thus, the distance in this case will be 0. This makes for stronger suggestions.
To apply this solution, a method named getNChars() is implemented. It accepts the following 2 arguments:
- dictWord: The dictionary word.
- N: The length of the user input.
The implementation of this method is given below:
String getNChars(String dictWord, int N, int T) {
if (dictWord.length() > N) {
String clippedWord = "";
for (int i = 0; i < N; i++) {
clippedWord += dictWord.charAt(i);
}
return clippedWord;
} else if (dictWord.length() == N) {
return dictWord;
} else if (dictWord.length() < N && Math.abs(dictWord.length() - N) <= T) {
return dictWord;
} else {
return null;
}
}When the length of dictWord is greater than N, it returns a string representing the first N characters from dictWord. If the length of dictWord is equal to N, then it will be returned unchanged. What if the length of dictWord is less than N? There’s an important step to take in this case.
As mentioned previously, the Levenshtein distance between 2 words will be small only when the 2 words are close in their lengths. It’s feasible to compare 2 words when the absolute difference in their lengths is 1 or 2 characters. Otherwise, it’s less likely that the words will match.
To deal with the situation when the length of dictWord is less than N, the getNChars() method returns the dictWord unchanged when the absolute difference between its length and N is smaller than or equal to a user-defined threshold T. Otherwise, the method returns null, which means there’s no need at all to calculate the distance. You can try values starting from 0 to T.
Here is the summary of the return output of the getNChars() method:
- If dictWord.length > N, return the first N characters of dictWord.
- If dictWord.length == N, return dictWord.
- If (dictWord.length < N) and (dictWord.length — N <= T), return dictWord.
- Else, return null.
A final note is that the Levenshtein distance is calculated based on the clipped word returned from the getNChars() method, but the complete word is what’s used for making suggestions.
After completing the implementation of the getNChars() method, the next step is to calculate the distance between the returned word and the user input.
Calculating the Distance
The previous tutorial created a method named returnSuggestions() that accepts the user input as the word argument and the number of words to return as suggestions in the numWords argument. It returns a String array holding the suggested words for autocompletion. The implementation of this method is given below:
String[] returnSuggestions(String word, int numWords) {
String[] dictWordDist = new String[20000];
BufferedReader reader;
int wordIdx = 0;
try {
int wordDistance;
reader = new BufferedReader(new InputStreamReader(getAssets().open("20k.txt")));
String line = reader.readLine();
String dictWord = "";
while (line != null) {
wordDistance = levenshtein(line.trim(), word);
dictWordDist[wordIdx] = wordDistance + "-" + line.trim();
line = reader.readLine();
wordIdx++;
}
reader.close();
} catch (IOException e) {
System.err.println("Failed to read the file.");
e.printStackTrace();
return null;
}
Arrays.sort(dictWordDist);
String[] closestWords = new String[numWords];
String currWordDist;
for (int i = 0; i < numWords; i++) {
currWordDist = dictWordDist[i];
String[] wordDetails = currWordDist.split("-");
closestWords[i] = wordDetails[1];
System.out.println(wordDetails[0] + " " + wordDetails[1]);
}
return closestWords;
}Here’s the specific line responsible for calculating the distance by calling the levenshtein() method, which accepts the 2 words to be compared: dictionary word line and user input word.
We are no longer interested in passing the entire dictionary word to this method and need to call the getNChars() method before that. For such a purpose, this method is called according to the next line. Note that the argument T is set to 0 which means there is no room for comparing a dictionary word of length less than the length of the user input. The result is saved in the dictWord variable.
Because the getNChars() method could return null, then an if statement is used to check the value of the dictWord variable. If not null, then the levenshtein() method is called normally to calculate the distance. Otherwise, the distance is set to a large number (i.e. 999) that makes it impossible to select this word in the list of suggestions, because the other words with lower distances will be selected.
Except for the above changes, everything remains unchanged. Here’s the edited implementation of the returnSuggestions() method.
String[] returnSuggestions(String word, int numWords) {
String[] dictWordDist = new String[20000];
BufferedReader reader;
int wordIdx = 0;
try {
int wordDistance;
reader = new BufferedReader(new InputStreamReader(getAssets().open("20k.txt")));
String line = reader.readLine();
String dictWord = "";
while (line != null) {
dictWord = getNChars(line.trim(), word.length(), 0);
if (dictWord != null) {
wordDistance = levenshtein(dictWord, word);
} else {
wordDistance = 999; // Setting the distance to a large number makes it impossible to select this word in the list of suggestions.
}
dictWordDist[wordIdx] = wordDistance + "-" + line.trim();
line = reader.readLine();
wordIdx++;
}
reader.close();
} catch (IOException e) {
System.err.println("Failed to read the file.");
e.printStackTrace();
return null;
}
Arrays.sort(dictWordDist);
String[] closestWords = new String[numWords];
String currWordDist;
for (int i = 0; i < numWords; i++) {
currWordDist = dictWordDist[i];
String[] wordDetails = currWordDist.split("-");
closestWords[i] = wordDetails[1];
System.out.println(wordDetails[0] + " " + wordDetails[1]);
}
return closestWords;
}Before using the getNChars() method, the next figure shows the 3 suggestions while the user is trying to type the word congratulations. The suggestions are not that good because the user input is compared to the entire word.
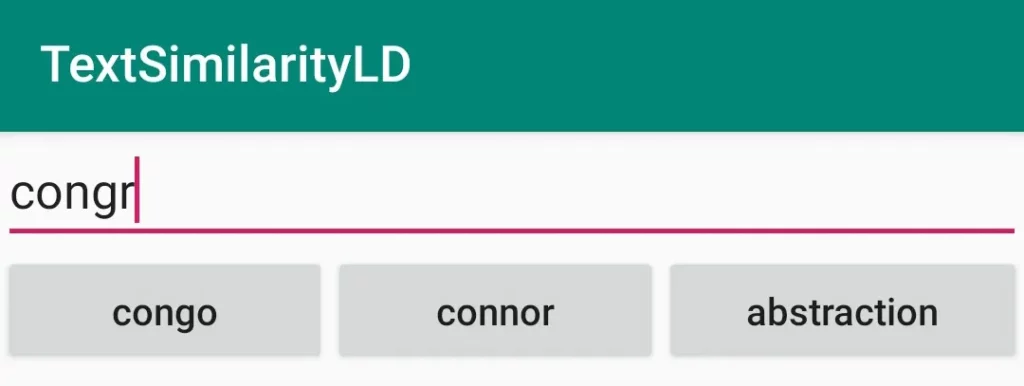
After using the getNChars() method to just return the words that are closer in length to the user input, the 3 suggestions are given in the next figure. The results are much better than before.

At this moment, the app can make pretty good suggestions. Another feature that will help speed up the process of making suggestions is to allow early exit when the distance exceeds a certain threshold. This is discussed in the next section.
Early exit
The smaller the Levenshtein distance between 2 words, the more likely they are matched. On the other hand, when the distance is high, this means the words are not similar.
While calculating the distance using the levenshtein() method, even if the distance between the 2 words is high, the method still continues until it’s finished.
At a state based on the current distance, and before completing the method, we might conclude that 2 words are not similar when the distance exceeds a pre-defined threshold.
This helps to both save time when we can reach the decision at an early stage and to enhance the suggestions by ignoring the words with distances far away from 0.
Using this technique, the method could exit earlier when the distance exceeds the chosen threshold. Before discussing the necessary changes, here’s the main structure of the levenshtein() method.
int levenshtein(String token1, String token2) {
...
int dist = 0;
for (int t2 = 1; t2 < token2.length(); t2++) {
...
for (int t1 = 1; t1 <= token1.length(); t1++) {
...
}
distances[token1.length()] = dist;
}
...
}The current method accepts just 2 arguments, which are token1 and token2, representing the 2 words. A third argument named distThreshold will be added representing the threshold (i.e. maximum allowed distance between the 2 words).
Based on the current value stored in the dist variable, we can decide whether the distance exceeded the threshold or not. Here’s how it looks.
If the distance exceeds the threshold, then the method returns the value 999, which makes it impossible to select the current word in the list of suggestions:
int levenshtein(String token1, String token2, int distThreshold) {
...
int dist = 0;
for (int t2 = 1; t2 < token2.length(); t2++) {
...
for (int t1 = 1; t1 <= token1.length(); t1++) {
...
}
distances[token1.length()] = dist;
if (dist > distThreshold) {
return 999;
}
}
...
}The complete method after using the threshold:
int levenshtein(String token1, String token2, int distThreshold) {
int[] distances = new int[token1.length() + 1];
for (int t1 = 1; t1 <= token1.length(); t1++) {
if (token1.charAt(t1 - 1) == token2.charAt(0)) {
distances[t1] = calcMin(distances[t1 - 1], t1 - 1, t1);
} else {
distances[t1] = calcMin(distances[t1 - 1], t1 - 1, t1) + 1;
}
}
int dist = 0;
for (int t2 = 1; t2 < token2.length(); t2++) {
dist = t2 + 1;
for (int t1 = 1; t1 <= token1.length(); t1++) {
int tempDist;
if (token1.charAt(t1 - 1) == token2.charAt(t2)) {
tempDist = calcMin(dist, distances[t1 - 1], distances[t1]);
} else {
tempDist = calcMin(dist, distances[t1 - 1], distances[t1]) + 1;
}
distances[t1 - 1] = dist;
dist = tempDist;
}
distances[token1.length()] = dist;
if (dist > distThreshold) {
return 999;
}
}
return dist;
}
static int calcMin(int a, int b, int c) {
if (a <= b && a <= c) {
return a;
} else if (b <= a && b <= c) {
return b;
} else {
return c;
}
}Remember to edit any calls to the levenshtein() method to pass the value of the third argument distThreshold.
Conclusion
This tutorial enhanced the word suggestions for autocompletion in our Android application. Initially, the Levenshtein distance was calculated between the user input and a dictionary.
But rather than using the complete words in the dictionary to calculate the distance, only the first N characters are used where N refers to the length of the user input.
Moreover, we enabled the levenshtein() method to support early exit when the distance exceeds a pre-defined threshold.

Comments 0 Responses