
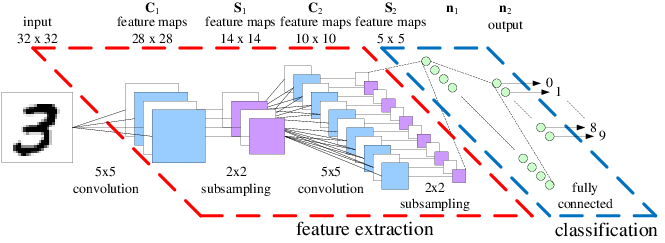
Convolutional Neural Networks (CNN) are frequently preferred in computer vision applications because of their successful results on object recognition and classification tasks. CNNs are composed of many neurons stacked together. Computing convolutions across neurons require a lot of computation, so pooling processes are often used to reduce the size of network layers.
Convolutional approaches make it possible to learn many complex features of our data with simple computations. By performing many matrix multiplications and summations on our input, we can arrive at an answer to our question.
I always hear how great CNNs are. When do they fail?
It’s true that CNNs have shown great success in solving object recognition and classification problems. However, they aren’t perfect. If a CNN is shown an object in an orientation it’s unfamiliar with or where objects appear in places that it’s not used to, its prediction task will likely fail.
For example, if you turn a face upside down, the network will no longer be able to recognize eyes, a nose, a mouth, and the spatial relationship between the two. Similarly, if you alter specific regions of the face (i.e. switch the positions of the eyes and nose), the network will be able to recognize the face— but it is no longer a real face.
In summary: CNNs learn statistical patterns in images, but they don’t learn fundamental concepts about what makes something actually look like a face.

Theorizing about why CNNs fail to learn concepts, Geoffrey Hinton, the Father of AI, focused on the pooling operation used to shrink the size and computation requirements of the network. He lamented:
The pooling layer was destroying information and making it impossible for networks to learn higher-level concepts. So he set out to develop a new architecture that didn’t rely so heavily on this operation.
The result: Capsule Networks
What is a Capsule Network?
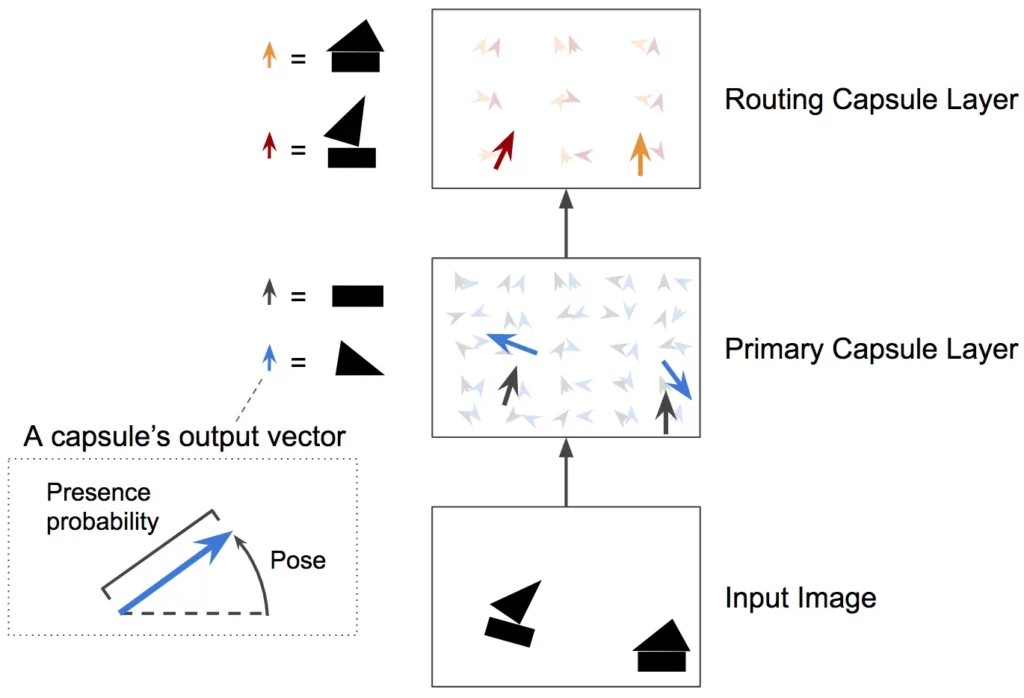
Hinton and Sabour borrowed ideas from neuroscience that suggest the brain is organized into modules called capsules. These capsules are particularly good at handling features of objects like pose (position, size, orientation), deformation, velocity, albedo, hue, texture, etc.
The brain, they theorize, must have a mechanism for routing low-level visual information to what it believes is the best capsule for handling it. Capsule networks and dynamic routing algorithms have been proposed as solutions to problems where convolutional neural network models are inadequate.

Capsules represent the various features of a particular entity that are present in the image. One very special feature is the existence of the instantiated entity in the image. The instantiated entity is a parameter such as position, size, orientation, deformation, velocity, albedo, hue, texture, etc.
An obvious way to represent its existence is by using a separate logistic unit, whose output is the probability that the entity exists [1]. To get better results than CNNs, we should use an iterative routing-by-agreement mechanism. These features are called instantiation parameters.
In the classic CNN model, such attributes of the object in the image are not obtained. The average / max-pooling layer reduces the size of a set of information while the size is reduced.
Squash Function
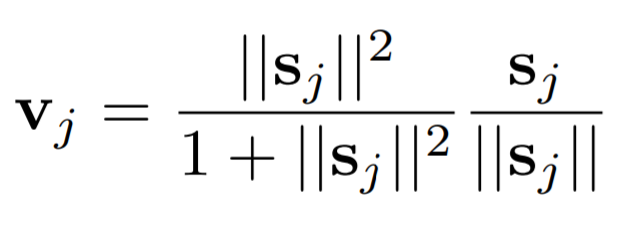
In deep neural networks, activation functions are simple mathematical operations applied to the output of layers. They are used to approximate non-linear relationships that exist in data. Activation layers typically act on scalar values—for example, normalizing each element in a vector so that it falls between 0 and 1.
In Capsule Networks, a special type of activation function called a squash function is used to normalize the magnitude of vectors, rather than the scalar elements themselves.

The outputs from these squash functions tell us how to route data through various capsules that are trained to learn different concepts. The properties of each object in the image are expressed in the vectors routing them. For example, the activations of a face may route different parts of an image to capsules that understand eyes, noses, mouths, and ears.
Application of the Capsule Network to the MNIST Dataset
Now, the next step is crucial:
Just like the layers at different levels of deep CNNs learn different semantic attributes of images (content, texture, style, etc.), capsules can be organized into different levels as well. Capsules at one level make predictions, learn about the shapes of objects, and pass those on to higher level capsules, which learn about orientations. When multiple predictions agree, a higher-level capsule becomes active. This process is described as dynamic routing, which I will talk about in more detail now.
So, let’s create a step-by-step capsule architecture for classifying the MNIST dataset:
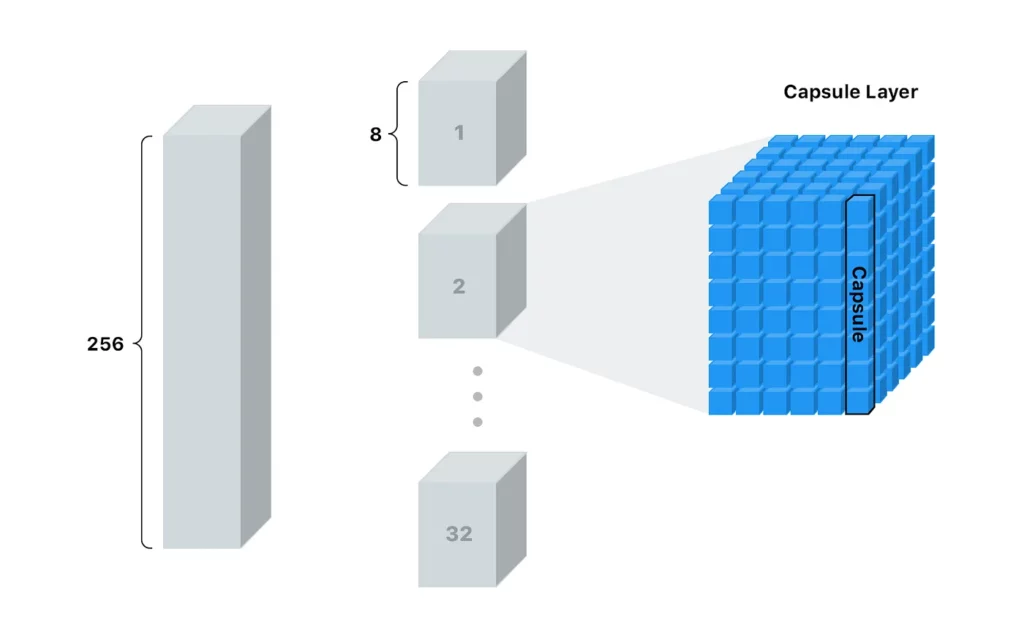
The first layer has a classic convolution layer. In the second layer, a convolution process is performed in the layer called the primary capsule, where the squash function is applied. Each primary capsule receives a small region of the image as input (called its receptive field), and it tries to detect the presence and pose of a particular pattern—for example, a circle.
Capsules in higher layers (called routing capsules) detect larger and more complex objects, such as the number 8, made up of two circles. Then they use a novel squashing function to guarantee these vectors have a length between 0 and 1.
A standard convolution layer is applied before the primary capsule layer and an output of 9x9x256 is obtained. A new convolution process with 32 channels is applied in the primary capsule layer with a stride of 2. However, this feature that separates it from other convolution processes is the function of squashing. Lastly, this gives the output of the primary capsules.

This gives a 6×6 output. However, in the capsule layer, a dynamic routing algorithm is implemented, such that 32 outputs of these 8-length outputs DigitCaps vectors are obtained as a result of the capsule layer with the third layer of dynamic routing (routing-by-agreement algorithm). The routing-by-agreement algorithm includes a few iterations of agreement (detection, and routing) update.
def CapsNet(input_shape, n_class, num_routing):
"""
MNIST Dataset for Capsule Networks.
: "input_shape" parameter: vdata shape, 3d, [w,h,c]
: "n_class" parameter: number of classes
: "num_routing" parameter: dynamic routing number of iteration
: Function output: two Keras model, first for training, second for evalaution.
`eval_model` used for traning at the same time.
"""
x = layers.Input(shape=input_shape )
# LAYER 1: Convolution Layer (Conv2D)
conv1 = layers.Conv2D(filters=256, kernel_size=9, strides=1, padding='valid', activation='relu', name='conv1')(x)
# LAYER 2: Conv2D squash activation, [None, num_capsule, dim_capsule] fro reshaping.
primarycaps = PrimaryCap(conv1, dim_capsule=8, n_channels=32, kernel_size=9, strides=2, padding='valid')
# LAYER 3: Capsule Layers. Run: Dynamic routing algorithm.
digitcaps = CapsuleLayer(num_capsule=n_class, dim_capsule=16, num_routing=num_routing,
name='digitcaps')(primarycaps)
# LAYER 4:
# If you use Tensorflow you can skip this session :)
out_caps = Length(name='capsnet')(digitcaps)The dynamic routing in capsulelayers.py is defined in the class CapsuleLayer (layers.Layer) function. Thanks to this calculation step, the vector values are small in areas where the object is not present in the image, while the dimensions of the vector in the detected areas vary depending on the attribute.
class CapsuleLayer(layers.Layer):
"""
The capsule layer. It is similar to Dense layer. Dense layer has `in_num` inputs, each is a scalar, the output of the
neuron from the former layer, and it has `out_num` output neurons. CapsuleLayer just expand the output of the neuron
from scalar to vector. So its input shape = [None, input_num_capsule, input_dim_capsule] and output shape =
[None, num_capsule, dim_capsule]. For Dense Layer, input_dim_capsule = dim_capsule = 1.
:param num_capsule: number of capsules in this layer
:param dim_capsule: dimension of the output vectors of the capsules in this layer
:param routings: number of iterations for the routing algorithm
"""
def __init__(self, num_capsule, dim_capsule, routings=3,
kernel_initializer='glorot_uniform',
**kwargs):
super(CapsuleLayer, self).__init__(**kwargs)
self.num_capsule = num_capsule
self.dim_capsule = dim_capsule
self.routings = routings
self.kernel_initializer = initializers.get(kernel_initializer)
def build(self, input_shape):
assert len(input_shape) >= 3, "The input Tensor should have shape=[None, input_num_capsule, input_dim_capsule]"
self.input_num_capsule = input_shape[1]
self.input_dim_capsule = input_shape[2]
# Transform matrix
self.W = self.add_weight(shape=[self.num_capsule, self.input_num_capsule,
self.dim_capsule, self.input_dim_capsule],
initializer=self.kernel_initializer,
name='W')
self.built = TrueYou can also find all the work here.
Test Performance 🏅
When testing with a 10,000-image test dataset, we achieved 99.61% accuracy for the MNIST dataset and 92.22% accuracy for the FASHION MNIST dataset have been obtained. Yeah!! 😎
For the MultiMNIST dataset, with 80% overlapping handwritten numbers, the performance of the Capsule Network appears to be impressively good when the data overlap, especially when compared to the CNN model.

50-Epoch Working Time for MNIST ⏳
As compared to the CNN, the training time for the capsule network is slower because of its computational complexity. Here’s a look at 50-epoch training time on various hardware and on a cloud server:


✔️Pros and ❌Cons of Capsule Networks
✔️Capsule networks have the highest success in the MNIST dataset when compared to other state-of-the-art techniques.
✔️It’s successful with smaller datasets. (By forcing the model to learn the feature variant in a capsule, it can extrapolate possible variants more effectively with less training data.)
✔️The routing-by-agreement algorithm allows us to distinguish objects in overlapping images.
✔️It’s easier to interpret the image with activation vectors.
✔️Capsule networks maintain information such as equivariance, hue, pose, albedo, texture, deformation, speed, and location of the object.
❌CIFAR10 does not succeed with the dataset compared to state of the art models.
❌Have not been tested on very large datasets.
❌Due to the routing-by-agreement algorithm, more time is required for training the model.
The application of the capsule network model with different routing algorithms shows that it’s a subject that needs more experimentation and is still developing.
Another Example
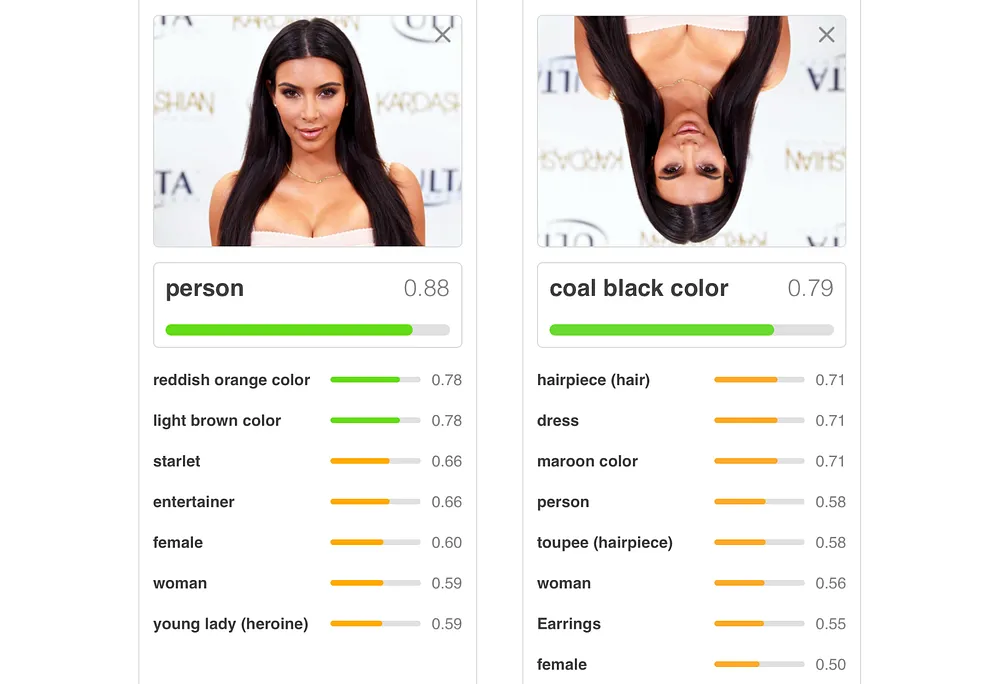
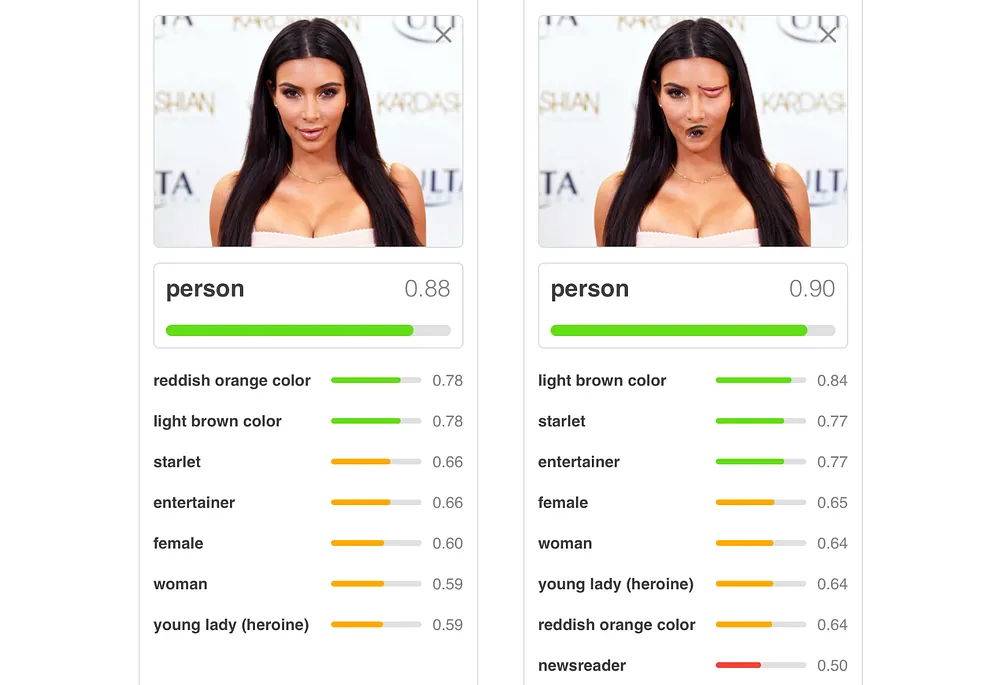
In the example shown above, when only the direction of the image of Kim Kardashian is changed, prediction accuracy drops significantly. In the image on the right, we can easily tell that an eye and her mouth are incorrectly placed and that this isn’t what a person is assumed to look like. Yet, we see a .90 prediction score.
A perfectly-trained CNN has some obstacles with this approach. Aside from being easily tricked by images with features in the incorrect locations, a CNN is also easily confused when viewing an image in a different orientation.
Beyond any doubt, CNNs can be affected by adversarial attacks. This is an important constraint that can cause security problems, especially when we embed a latent pattern into an object to make it look like something else. However, as we’ve learned, we can solve this problem with Capsule Networks!
✨The models of Capsule Networks are worthwhile and promising!
📝Our academic paper about Capsule Networks:
Recognition of Sign Language Using Capsule Networks
Hearing and speech impaired persons continue to communicate with the help of lip-reading or hand and face movements (i.e. sign language). Capsule Networks can help in ensuring that disabled people can not only participate fully in life but also increase the quality of life through healthy and effective communication with other people.
In this work; digits of the sign language were recognized with 94.2% validation accuracy by Capsule Networks.


References
[1] Sabour, S., Frosst, N. ve Hinton, G.E., “Dynamic Routing Between Capsules’’, arXiv preprint arXiv:1710.09829, 2017.
[2]Hinton, G. E., Krizhevsky A. ve Wang, S. D. “Transforming Auto-encoders.” International Conference on Artificial Neural Networks. Springer, Berlin, Heidelberg, 2011.
[3] CSC2535: 2013 Advanced Machine Learning Taking Inverse Graphics Seriously, Geoffrey Hinton Department of Computer Science University of Toronto, 2013.
[4] Capsule Network Implementation of MNIST dataset (in Turkish explanation, Deep Learning Türkiye, kapsul-agi-capsule-network.
[5] Recognition of Sign Language Using Capsule Networks, Fuat Beşer, Merve Ayyüce KIZRAK, Bülent BOLAT, Tülay YILDIRIM, https://github.com/ayyucekizrak/Kapsul-Aglari-ile-Isaret-Dili-Tanima

Comments 0 Responses