
We’re living in an era of transition from inventions of the Renaissance to the technological revolution of automation. Even so, a lot of valuable records and information are still locked inside unstructured documents. Transforming these documents into digital format to perform various operations requires complex AI techniques on top of simple optical character recognition.
Today, a number of industries including medicine, finance, law, and real-estate rely on human-intensive processes to convert forms and other documents into digital formats. Be it patients history locked in medical record files of hospitals, mortgage applications, or tax forms, these transcriptions all requires effort and human intervention on top of simple OCR techniques — that used to detect text without keeping the composition of document intact — to convert them into valuable digital assets.
To help solve this problem, Amazon introduced Textract, a fully-managed machine learning service that enables its web service customers to automate large scale document workflows by processing millions of pages in a matter of hours. With Textract, users can extract structured information from many file formats with no machine learning knowledge.
Amazon Textract Features
Textract goes beyond traditional OCR and provides a lot of ML capabilities that make information extraction efficient, smart, and fast. Here are a few highlights.
Automating Forms Input
In traditional OCR, without hard coding bounding boxes or implementing complex logic, it isn’t possible to retain relationships between the parts of text extracted from a given document.
Textract understands forms and extracts text blocks, maintaining relationships between them. On an image of the form, Textract will output a key-value pair with these attributes as key and appropriate values against each of them.
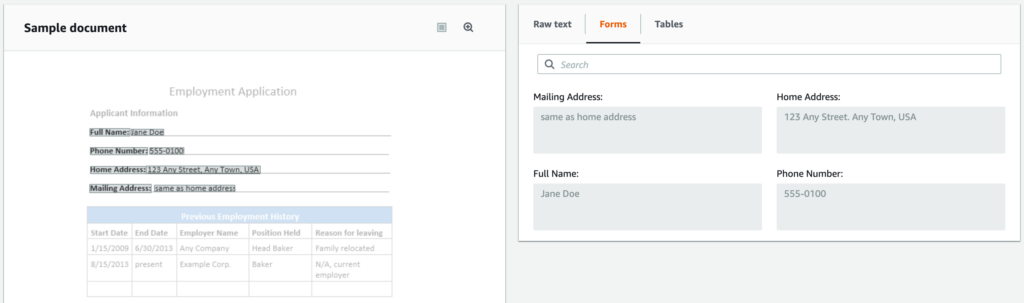
As seen above, employment application form that has employe’s full name, phone number, house & mailing addresses, output from Textract will be a json object with key “Full Name” and text against associated to it as value.
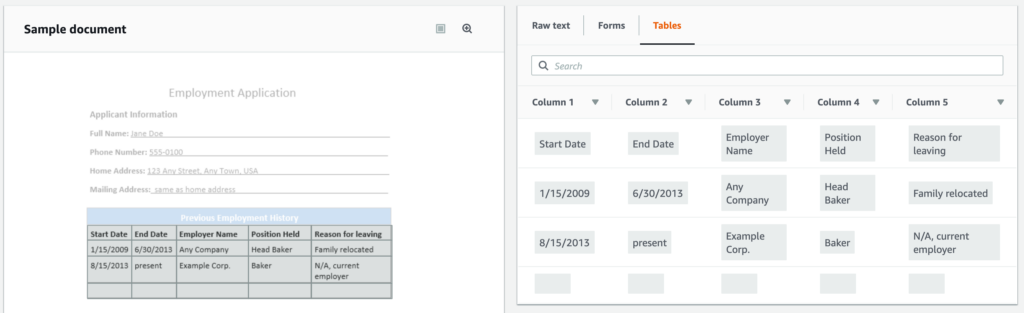
Converting Tables
When extracting text from images of documents, Textract automatically detects tables and keeps the composition of data represented in those tables intact. The output of such data is in tabular format, which allows the user to store them easily in their databases. This is helpful for documents that are largely composed of structured data—such as financial reports or medical records—that have column names in the top row of the table followed by rows of individual entries.
Keep Reading Format Intact — Multi-Column
Consider an example of extracting news from old-age newspapers, where for more readability, text was presented in a multi-column format. Textract provides a bounding box and geometry around text blocks that allow users to place the extracted text in the desired manner.
Quality Assurance — Confidence Controls
Textract outputs the text blocks extracted with a confidence level. This allows users to make informed decisions about how they want to use the results. Users can set the level where human intervention is required for correction or verification, depending upon the requirements.
Use Cases
Efficient document processing workflows
Today, many organizations spend a lot of time and money on document extraction workflows. But with Textract, the cost of these workflows can be reduced by quite a lot. With the growing efficiency of Textract’s ML models, these costs will continue to diminish over time, as less human intervention will be required.
Making documents searchable
Since Textract keeps the composition of extracted information intact, it’s easier to perform searches and other analysis on information quickly. For example, a hospital could extract contact information of all blood donors with group O+, or a mortgage department could extract all contracts with an interest rate less than 2%.
Information Ready for AI
Since the context and structure of extracted information becomes available, it also is easier to perform other AI tasks on this data. For example, structured medical record data can be used to perform a historical analysis on lab reports of patients admitted under certain medical conditions.
Production Readiness — Customers
Textract already has customers using the service, including organizations such as PwC, Healthfirst, Informed Inc, UiPath, and The Global and Mail. Healthfirst is using Textract along with Amazon Comprehend Medical to convert medical documents into meaningful data to improve care coordination, drive quality outcomes, and ensure appropriate reimbursement for members under our coverage.
Additionally, The Met Office, UK’s national weather service, is using Textract to digitize millions of historical weather observations from document archives. This will improve our understanding of climate variability and change.
A note about data privacy
From a monetary perspective, Amazon isn’t charging much for this service. But in terms of data privacy, Amazon Textract may store and use document and image inputs processed by the service, solely to provide and maintain the service and to improve and develop the quality of Amazon Textract and other Amazon machine learning/artificial intelligence technologies.
Conclusion
Amazon Textract looks a promising addition to recent AI advancements. It will allow a lot of organizations to make better use of historical data trapped inside traditional documents. This will also help organizations convert their current document processing workflows and make them more efficient.
Discuss this on HackerNews or Reddit
Comments 0 Responses